
RapidMiner Studio具有可视化工作流程设计和完全自动化的综合数据科学平台。RapidMiner的数据科学平台为各行各业的 40,000 多个组织带来变革性的业务影响,以增加收入、降低成本并避免风险。
安装教程
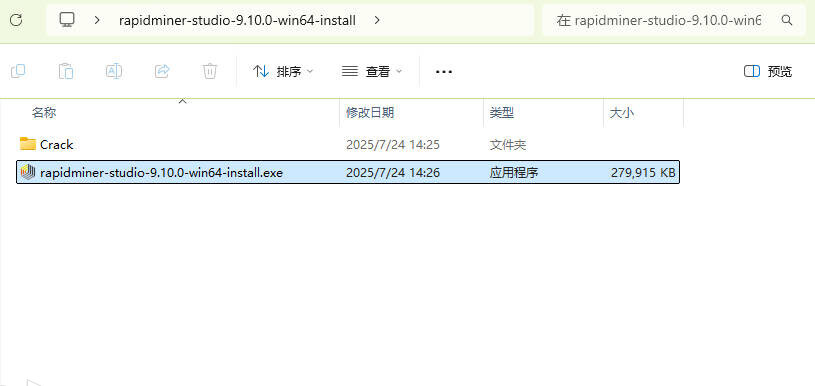
1在本站下载解压,双击安装 rapidminer-studio-9.10.0-win64-install.exe
2点击下一步
3选择第一项“I agree”(我接受许可协议的条款),再点击“next”进入下一步
4选择安装位置,默认路径为“C:\Program Files\RapidMiner\RapidMiner Studio”
5软件安装需要一些时间请耐心等待即可
6当安装结束后先不要运行软件,点击“finish”退出安装向导
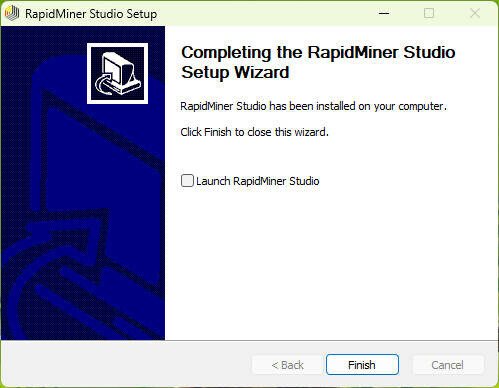
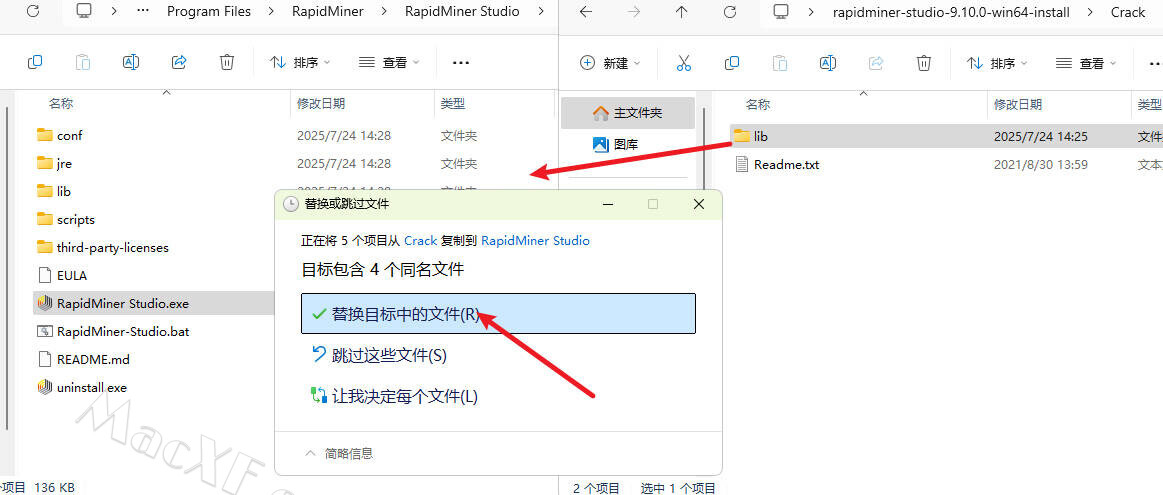
7回到刚才下载的数据包中将“Crack”文件夹中的破解文件“lib”复制到软件安装目录中,默认路径为:C:\Program Files\RapidMiner\RapidMiner Studio在跳出的窗口中点击第一项“替换目标中的文件”
8双击进入软件在跳出的激活窗口中点击“Manually enter a license key”
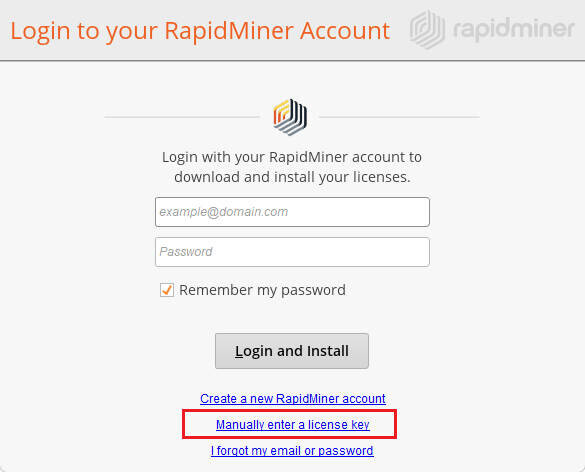
10再次进入刚才下载的数据包打开“Readme.txt”,复制里面的注册信息到软件的注册窗口中。
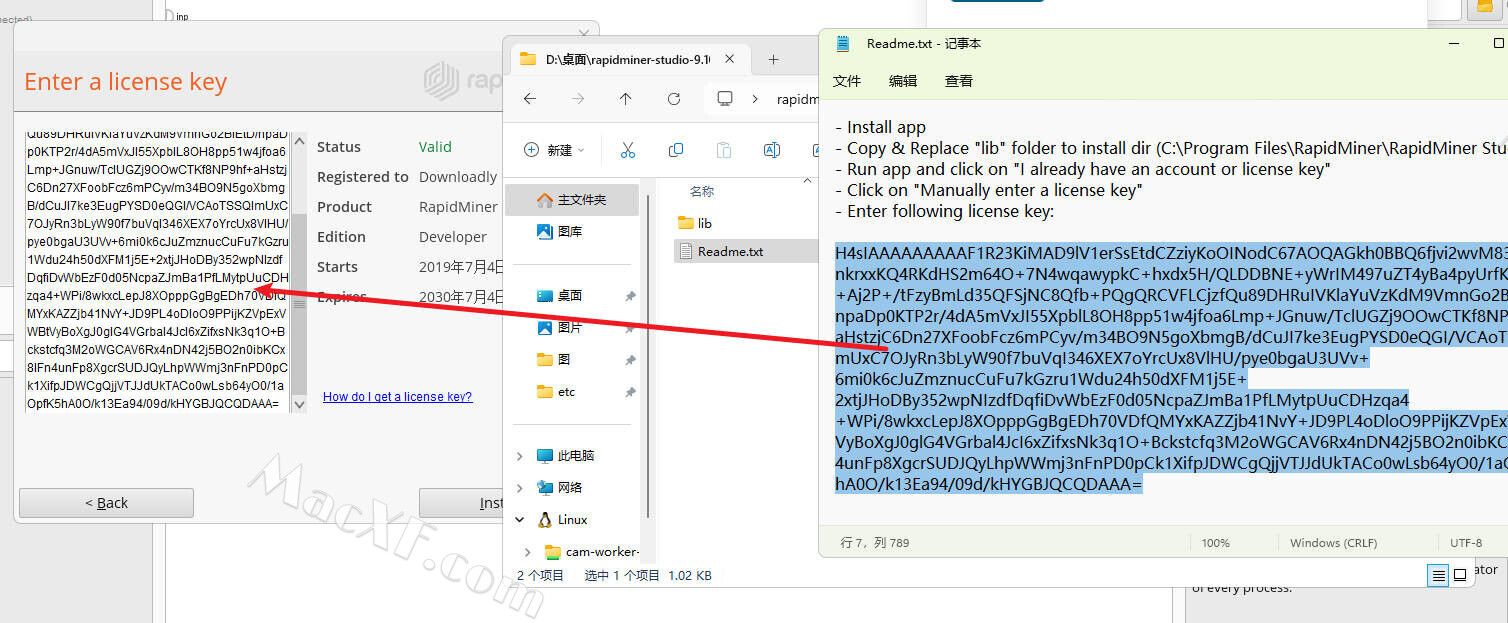
11最后运行软件即可开始使用咯,破解完成!
RapidMiner Studio 9.10功能特点
-
可视化工作流设计器:提高从分析师到专家的整个数据科学团队的生产力,在拖放式可视界面中加速并自动创建预测模型,1500+的丰富库 算法和函数确保了任何用例的最佳模型,针对常见使用情形的预构建模板,包括客户流失、预测性维护、欺诈检测等
-
连接到任何数据源:处理所有数据,无论数据位于何处即时创建指向数据库、企业数据仓库、数据湖、云存储、业务应用程序和社交媒体的点击式连接 随时随地轻松重复使用连接与需要访问的任何人共享它们通过RapidMiner 市场的扩展连接到新资源
-
自动化的数据库内处理 :在数据库内运行数据准备和 ETL,使您的数据针对高级分析进行优化查询和检索数据,而无需编写复杂的 SQL,利用高度可扩展的数据库集群的强大功能,支持 MySQL、PostgreSQL 和 Google BigQuery
-
数据可视化与探索:评估数据的健康度、完整性和质量,通过散点图、直方图、线图、平行坐标、箱形图等了解模式、趋势和分布,快速找到并修复常见的数据质量问题,包括丢失的值和异常值。使用健壮的统计概述和超过30种交互式可视化探索数据
相关软件
相关专题
数据管理软件
进入专题
Disk Drill Enterprise(数据恢复软件)

MiniTool Power Data Recovery 11 (数据还原应用)

GiliSoft File Lock Pro (数据保护软件)

HeidiSql (数据库可视化工具)

DBeaver Ultimate(数据库管理软件)

Navicat Premium Essentials(数据库开发工具)

Full Convert Ultimate 21(数据库转换工具)

Valentina Studio Pro(数据库管理软件)

Navicat 15 for MariaDB(数据库管理软件)

Navicat 15 for Oracle(数据库管理软件)



